The cloud is powering a lot of successful businesses that help millions of people all around the globe.
The goal for web developers is to make sure that the end-user will have a pleasant and smooth experience. Sometimes, some tasks on the web may take a lot of time to complete making web surfing slow and annoying.
This is where a worker role comes in place.
In this article, I’ll describe the lifecycle of a worker role.
Also, we’ll take a deep dive into some programming paradigms that work well with our roles, analyzing their pros and cons.
Table of Contents
Everything described here will be backed up by different examples and some practices that are healthy for the development of sustainable and scalable worker roles.
What is a Worker’s Role?
In Azure, there are two roles that run your code:
- The first one is called a web role and it can be viewed as a web server because it communicates with the outside world.
- The second one it’s known as a worker role that can be viewed as back-end servers since they are used for running tasks that require a longer time to finish or that can be computed asynchronously.
They can be used for implementing different parallel models but the most popular one is producer-consumer since they are message-based.
They receive that message by polling a queue or some shared storage. The amount of worker roles that need to start in the cloud is defined by your application service model.
This can be incredibly useful since the worker role will allow you to execute, for example, some tasks that will fire up at a certain time in a day, and if the business scales all you must do is to increase the number of instances of your worker role until it meets your needs.
The only trick is to be aware since by default Windows Azure does not contain a job scheduler.
A Practical Guide to the Worker Role
A worker role is written in .NET and as I was saying before, it relies on messages. They can receive the messages that are going to process in a push or pull fashion.
The push method represents the active method since you are giving the worker role the message directly.
And the pull method would be the passive approach because you would have the role instances pulling the data out of a shared resource.
Since we are dealing with a shared resource this means that we might need a conflict-control mechanism like Azure Queue because of the possibility of “unanimous computing”.
A worker role is written in .NET and it relies on messages.
We know that a Web Role is limited to HTTP/S protocols and can have two endpoints at most. But on the other hand, a worker role is more flexible and can bypass this problem in several ways.
For example, let’s take three worker role designs and explain what they would represent:
- All instances of a worker role pull a shared resource (queue) in order to get the work, acting as a pull model
- Outside Azure there is a producer that directly sends messages to the worker role instances, acting on the push model
- A producer that is inside Azure sends messages to the worker role instances, acting on the push model
The Queue Approach
The most popular approach is exactly the first and it even represents the starting template in Visual Studio when creating a worker role.
In this approach, the worker role will constantly receive the data from a queue and process it, if there is no data, it is going to wait five seconds and poll the queue once again.
A natural question to ask would be, “why not process the table directly?!”.
Well, the worker roles are useful because they can scale by increasing the number of their instances. This means that you have two major problems:
- One would be that two or more instances process the same data and it would be a waste of processing power.
- And the other problem is involving the durability of the work because if a worker role instance fails to do its work, that data inside is gone forever, and it will freeze. The system administrator would have to go in and manually reset the status property back to new. This can be solved by creating a concurrency mechanism designed for failure recoverability. But this is what Queue service is for. It is designed to offer a way to distribute the work among instances and to recover easily in case of a failure. We must keep in mind that in the cloud, failures happen all the time and that data must recover, and the job restarted even if this happens on a different server.
Outsider to Worker Role
When it comes to communicating to the outside world, worker roles are the best, since their use is to receive messages from the internet (browser) and respond with a message (HTML).
There are two ways in which a worker role can be exposed to the internet:
- one way is as an input service — available to the load balancer and externally.
- and the other way is as an internal service, which is not behind a load balancer and is only visible to your other role instances.
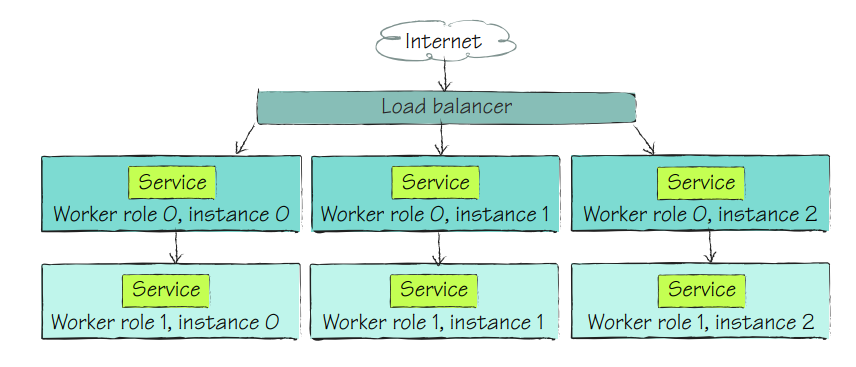
One thing to keep in mind is that a worker role cannot be hosted on IIS so the only real option is to build the service as a WCF service.
So, exposing services to the world seems like a great idea, but sometimes you want those endpoints to be there just for your use. In this case, you should rely on inter-role communication.
Inter-role Communication
Sometimes you just want to keep your service private, but you still want some information to pass from one service to another.
One approach is to use a queue, but this will not do the trick every time.
This way of dealing with communication comes at a cost.
You must be aware that you will be able to directly access an individual role instance which means there is no separation that can deal with load balancing.
In a similar fashion, if you are communicating with an instance and it fails or goes down, the work is gone and cannot be retrieved.
So, all you must do to enable inter-role communication is to add an internal endpoint in the same way you add an input endpoint.
The internal endpoint is like the external endpoint, but your service does not know about the instances that are running in parallel and they do not have any load balancing system available.
Choosing the right approach can be hard since all three seem like a satisfactory solution. But this depends on the situation.
The input solution is great when you want to abuse Azure’s load balancer.
And internal endpoint when dealing with synchronous problems or instance-explicit tasks.
Use Cases for Worker Roles
Worker roles can be used for a lot of things, but the most important ones would be to offload work from the frontend, break a huge process into smaller ones that are connected, or even to integrate multithreading easily and safely in your application.
One notable example would be the way a user adds something to its cart and then checks out with an online retailer. The way the retailer processes your cart/order would be a skillful use for worker roles in the cloud.
The checkout process is usually split into two parts:
- The processing and the user-friendly part: in the user-friendly part once you fill your cart and proceed to check out the store will collect all the data from you that is needed for the transaction and send you a thank you email with an order id. That order ID represents the ID in the queue of processing orders (this ID can be changed).
- The second part is where the worker role comes in handy. It processes your order by checking the stock and filling in all other tasks that must be done, and after they are done it will send you a detailed email with your order.
This simple example shows just how powerful a worker can be.
By splitting the work into two pieces, the user will have a smoother buying experience since all the checkout processes will be fast.
This always works amazingly with scaling horizontally since all you need to do is scale it up — it gives more processing power and sometimes that is not needed if you do not have a constant flow of customers.
For example, once an order is in the processing queue, that can be picked by any of the instances of the worker role and be processed even after three hours.
One advantage here is the speed by taking out a lot of loads off the web servers. This also is a great approach when it comes to servers failing. Since if your instance fails (whatever the reason), another processing worker role will pick it up and try to solve it.
When porting an app to Azure platform, for example, you must keep in mind that debugging is difficult for multithreading apps.
But if you are doing some asynchronous programming that should be ok (one thread for example).
Sometimes worker roles can be simulated to maintain the logical separation.
But you must create your architecture in such a way that it can be easily replaced by a real worker role. Simulating a worker role at the core has the same principle: it will rely on a queue and message passing.
And for the continuous running there is a trick: launch the process on a separate thread during the Session_Start event of the global.asax and this will allow you to mimic the behavior of a real worker role.
One thing to keep in mind is that Fabric Controller will not recognize your simulated worker role so he will not manage it.
The load balancer will also ignore your simulated worker role, and if something happens to that simulated worker it will take down the whole web instance and cascade into even more problems.
If we are dealing with a big worker role sometimes that itself can take time.
So, one solution would be to break it into multiple pieces, and since they are message-centric, to group them and consume the queue.
A big worker role that takes up too much time to complete the job is a problem because the longer it takes the more exposed your system is, and it is harder to scale.
This problem appears when a worker role tries to process a chunk of big messages and it is known as “pig in a python”.
“Pig in a python” — this problem appears when a python eats a pig, and the digestion process could take months and it cannot do anything during that time.
In an analogous manner, a chunk of work that is too big, running through your system can block the progress of improving the cost.
To solve this problem, you should break your process into a smaller one.
However, you must keep in mind that at this level, the latency of communicating with the queue in message-based systems may introduce more overhead than is desired.
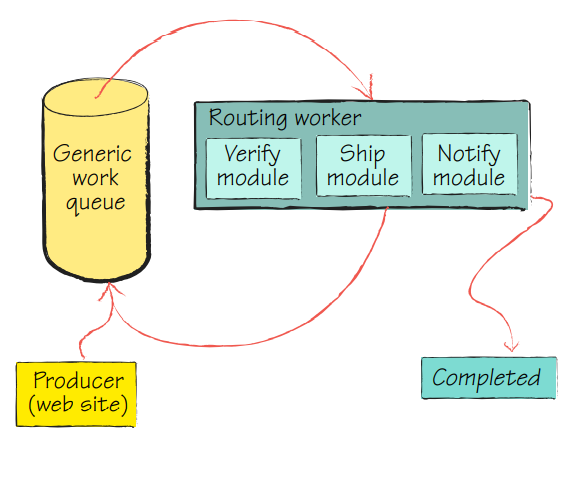
For example, if you would have four tasks for a worker role, it would be wise to split that into four different worker roles that verify and execute the command, and if one of them fails to notice human personnel that will correct the order and resubmits it to the worker queue.
This process is called repair and resubmit, and it is vital for some architecture.
This approach is amazing, but it also comes with a cost, you will have more worker roles to manage, and eventually, you will be in the “pig in python” scenario, and sure, you can scale up, but the costs will also go up.
A good practice would be to make sure that a worker role can also process all states besides having a specific specialization.
The trick or the holy grail would have a worker role that acts as a router and will distribute the work inside it according to the situation. Like in the image below.
Conclusions
In conclusion, worker roles are amazing, and they can save you a lot of money and improve the workflow in general.
I have not covered their interaction with local storage because it is highly recommended to avoid it because of certain limitations.
The worker role has sustained a lot of huge architecture and allowed countless customers to be satisfied. However, as it is said, with great powers comes great responsibility because they can be difficult to manage.
Resources:
- Azure in Action — ISBN:9781935182481, Author: Chris Hay Brian H. Prince –main source
- https://docs.microsoft.com/en-us/azure/cloud-services/cloud-services-choose-me


